Mapnik Generative AI workflow¶
Alexander Dunkel, Institute of Cartography, TU Dresden

Mapnik rendering based on stable diffusion generative AI and social media data.
In order to be able to place images on a map, we need simplified illustrations that convey textual information as graphics. These graphics should ideally be isolated on white, so they can be used as an overlay on a map. Here, we use a LoRa (Low-Rank Adaption) that produces minimalist illustrations in japanese line drawing styles from the given prompts. ^1.
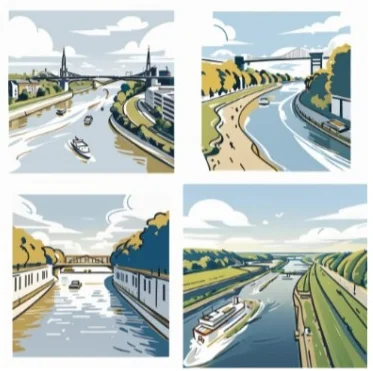
This is an example output batch for the prompt river, elbe, aerial.
We will generate graphics based on both collections of tags and single emoji. The central stable diffusion workflow is shown in the following schema for emoji:
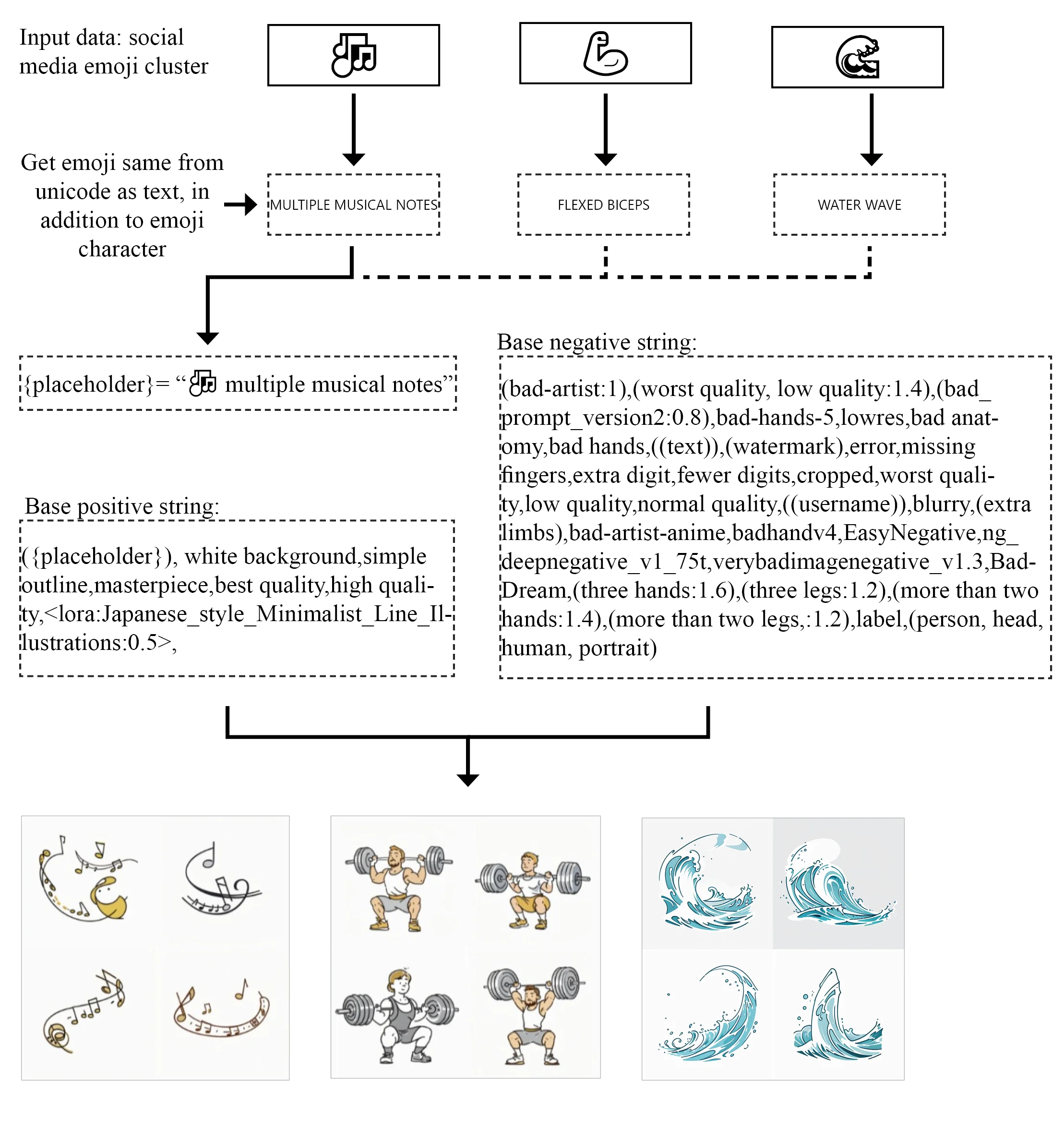
Steps:
- Emoji from social media cluster
- Get text for emoji, in addition to the emoji character itself
- Combine with base positive prompt and base negative prompt
- Generate Images
- Place images on map in mapnik, scale based on frequency of emoji cluster
There is more to it. Major challenges inhere:
- connect via API from Jupyter Lab to Stable Diffusion in HPC cluster
- automatically generate images recursively for all clusters through the API, fetch images, name and store locally
- use Mapnik to place images, scale size according to cluster frequency
- Prevent overlap, produce final map without artifacts at the border of images/icons and edges
- combine
tagsandemojiimages to generate a balanced output map with objects, people, activities and associations
Prepare environment¶
To run this notebook, as a starting point, you have two options:
1. Create an environment with the packages and versions shown in the following cell.
As a starting point, you may use the latest conda environment_default.yml from our CartoLab docker container.
2. If docker is available to you, we suggest to use the Carto-Lab Docker Container (the mapnik-version)
Clone the repository and edit your .env value to point to the repsitory, where this notebook can be found, e.g.:
git clone https://gitlab.vgiscience.de/lbsn/tools/jupyterlab.git
cd jupyterlab
cp .env.example .env
nano .env
## Enter:
# JUPYTER_NOTEBOOKS=~/notebooks/mapnik_stablediffusion
# TAG=v0.12.3
docker network create lbsn-network
docker-compose pull && docker-compose up -d
Load dependencies:
from numba.core.errors import NumbaDeprecationWarning, NumbaPendingDeprecationWarning
import warnings
warnings.simplefilter('ignore', category=NumbaDeprecationWarning)
warnings.simplefilter('ignore', category=NumbaPendingDeprecationWarning)
import sys
import math
import fiona
import rasterio
import numpy as np
import contextily as cx
import mapclassify as mc
import libpysal as lps
import json
import requests
import io
import base64
import matplotlib.pyplot as plt
from PIL import Image, PngImagePlugin
from IPython import display
from contextily import Place
from typing import Tuple, Optional, List, Dict, Any
from rasterio.plot import show as rioshow
from pathlib import Path
from esda.getisord import G_Local
from shapely.geometry import shape
We are using a number of helper functions from py/modules/tools.py to classify values.
module_path = str(Path.cwd().parents[0] / "py")
if module_path not in sys.path:
sys.path.append(module_path)
from modules.base import tools, raster
Activate autoreload of changed python files:
%load_ext autoreload
%autoreload 2
Test Mapnik bindings
!/usr/bin/python3 -c "import mapnik;print(mapnik.__file__)"
Parameters¶
Define initial parameters that affect processing
INPUT: Path = Path.cwd().parents[0] / "input" # define path to input and working directory (shapefiles, stylesheets etc.)
OUTPUT: Path = Path.cwd().parents[0] / "output" # define path to output directory (map, notebook html etc.)
images = OUTPUT / "images"
TMP: Path = INPUT / "intermediate" # folder to store intermediate data
TMP_AI: Path = INPUT / "intermediate" / "gen-ai" # folder to store generative ai data
MAP_X: int = 2500 # x dimensions of the final map, in pixels
MAP_Y: int = 1400 # y dimensions of the final map, in pixels
for folder in [OUTPUT, TMP_AI, images]:
folder.mkdir(exist_ok=True, parents=True)
Files¶
The tagmaps-mapnik workflow for preparing the data for the map below is described in a previous notebook:
Show the directory tree:
tools.tree(Path.cwd().parents[0])
Test creating a (tag) map¶
stylesheet = "tagmap_production.xml"
output_name = "tagmap_production.png"
Set global font path variable for mapnik.
!export MAPNIK_FONT_PATH=/fonts
Download font set for Segoe UI Symbol Regular, Aerial Bold, and Noto Sans Regular
!wget https://raw.githubusercontent.com/mrbvrz/segoe-ui-linux/master/font/seguisym.ttf \
https://raw.githubusercontent.com/foursquare/foursquair/master/src/assets/fonts/Arial%20Bold.ttf \
https://github.com/openmaptiles/fonts/raw/master/noto-sans/NotoSans-Regular.ttf \
--directory-prefix {TMP}/fonts -nc --quiet
!rm /fonts && ln -s {TMP}/fonts /fonts
Create tagmap using mapnik_cli
%%time
!/usr/bin/python3 -m mapnik_cli \
--stylesheet_name {stylesheet} \
--output_name {output_name} \
--map_dimensiony_x {MAP_X} \
--map_dimensiony_y {MAP_Y} \
--input_path {INPUT} \
--output_path {OUTPUT} \
--bbox '412602.4948451808,5654046.735233658,413809.2816068467,5655787.42471083'
display.Image(f'{OUTPUT}/{output_name}')

Connect to stable diffusion API¶
We are using the API that is made available by automatic1111's stable-diffusion-webui.
The first step is to enable the API with the following variable:
export COMMANDLINE_ARGS="--xformers --api --nowebui"
--xformers is entirely optional and has nothing to do with the API. Furthermore, I was only able to get the /sdapi endpoints with the additional flag --nowebui, see #6918.
The second step is to make a backwards ssh tunnel to our host running jupyter lab docker.
The tunneling here can be confusing: Our stable-diffusion CUDA environment likely runs somewhere else. In my case, I use the HPC environment that is made available by my university.
If you run this all on your local machine, nothings needs to be done.
The following will establish a reverse tunnel bound to port 7861 on both sides. The port 7861 is only necessary if you run --nowebui, otherwise it will be port 7860.
ssh user@jupyter.host -o ExitOnForwardFailure=yes \
-o ServerAliveInterval=120 -f -R \
:7861:127.0.0.1:7861 -p 22 -N; \
./webui.sh
A third, optional step is to use a forward ssh tunnel to connect to your Jupyter host. If this is your local machine, nothings needs to be done.
ssh user@jupyter.host -L :7861:127.0.0.1:7861 -p 22 -N -v
Also see my blog post on tunneling here.
Finally, if you are using CartoLab-Docker as your Jupyter instance, to be able to forward connect to the port 7861 that is listening on the docker host, we need to change the docker-compose.yml,
disable the custom network from CartoLab Docker and add network_mode: "host". Afterwards, check with:
!wget -S --spider 127.0.0.1:7861/docs
If you see a HTTP/1.1 200 OK, everything works.
Test API¶
Follow the webui guide to test the API:
payload = {
"prompt": "Big tree on white background",
"steps": 50
}
%%time
response = requests.post(url=f'http://127.0.0.1:7861/sdapi/v1/txt2img', json=payload)
def process_response(
response: str, target_size: Optional[int] = None, show: Optional[bool] = True,
output: Path = OUTPUT, save_name: Optional[str] = None):
"""Get Images from json response and plot preview"""
if target_size is None:
target_size = 250
r = response.json()
for ix, i in enumerate(r['images']):
image = Image.open(io.BytesIO(base64.b64decode(i.split(",",1)[0])))
if save_name is not None:
fname = f"{save_name}.png"
if ix > 0:
fname = f"{save_name}_{ix:02}.png"
image.save(output / "images" / fname, "PNG")
if not show:
continue
image.thumbnail(
(target_size, target_size), Image.Resampling.LANCZOS)
image.show()
process_response(response)

SD Parameters¶
Have a look at http://localhost:7861/docs#/default/text2imgapi_sdapi_v1_txt2img_post for parameters.
We can also get options, such as the currently loaded checkpoint:
APIURL = "http://127.0.0.1:7861"
response = requests.get(url=f'{APIURL}/sdapi/v1/options')
response.json()["sd_model_checkpoint"]
Here, we use a Model/Checkpoint/Merge called hellofunnycity, which provides a general cartoon style. The model page recommends to set CLIP skip parameter to 2. However, I observed more overtraining steps below, which is why I leave this at 1 - feel free to change and test below.
We also use a VAE (Variable Autoencoder) that helps increase sharpness ( sd-vae-ft-mse-original) of generated images. After downloading the VAE, refresh with:
requests.post(url=f'{APIURL}/sdapi/v1/refresh-vae')
Then post options to the API:
payload = {
"CLIP_stop_at_last_layers": 1,
"sd_vae":"vae-ft-mse-840000-ema-pruned.safetensors",
}
requests.post(url=f'{APIURL}/sdapi/v1/options', json=payload)
A Response 200 means: Ok.
Other parameters are applied on a job-by-job basis, such as the number of steps. We store these settings in a global dictionary:
SD_CONFIG = {
"steps": 50,
}
Turn generation of images into method.
def generate(
prompt: str, save_name: Optional[str] = None,
show: Optional[bool] = True, sd_config: Optional[dict] = SD_CONFIG,
api_url: str = None, negative_prompt: Optional[str] = None):
"""
Generate image via SD prompt, optionally save to disk and show image
Args:
prompt: Text prompt to generate image. Required.
save_name: Name to save image to disk. Without extension. Optional.
show: Show image. Optional. Default: True
steps: Sampling steps. Default: 50.
api_url: URL to SDAPI v1. Optional.
"""
if api_url is None:
api_url = 'http://127.0.0.1:7861/sdapi/v1/txt2img'
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt
}
payload.update(sd_config)
response = requests.post(url=api_url, json=payload)
process_response(response, save_name=save_name, show=show)
Many parameters are available for SD image generation. The prompt has one of the biggest impact on generated images. Both positive prompt and a negative prompt can be specified.
Based on the introduction, we use a base template for negative and positive prompt for how we want to generate the image (style) and then substitute a part for what we actually want to generate.
Short intro on SD prompts:
- Instructions are separated by comma, strictly this is not nessessary, but it helps better read the prompt
(x)emphasis. Multiplies the attention to x by 1.1. Equivalent to (x:1.1)[x]de-emphasis, divides the attention to x by 1.1. Approximate to (x:0.91)(x:number)emphasis if number > 1, deemphasis if < 1. Multiply the attention by number.<>is for embeddings and LoRA. Decimals equally modify their weight.
These are our sample base prompts:
BASE_PROMPT_POS: str = \
"white background,simple outline,masterpiece,best quality,high quality," \
"<lora:Japanese_style_Minimalist_Line_Illustrations:0.2>"
BASE_PROMPT_NEG: str = \
"(bad-artist:1),(worst quality, low quality:1.4),lowres,bad anatomy,bad hands," \
"((text)),(watermark),error,missing fingers,extra digit,fewer digits,cropped,worst quality," \
"low quality,normal quality,((username)),blurry,(extra limbs),BadDream," \
"(three hands:1.6),(three legs:1.2),(more than two hands:1.4),(more than two legs,:1.2)," \
"label,(isometric), (square)"
def concat_prompt(prompt: str, base_prompt_pos: str = BASE_PROMPT_POS) -> str:
"""Returns base prompt substitute with task prompt"""
return f'{prompt},{base_prompt_pos}'
PROMPT: str = "(Big tree on white background)"
generate(concat_prompt(PROMPT), negative_prompt=BASE_PROMPT_NEG, save_name="test_image")

Remove background¶
For some images, the image background is not fully white. We can use rembg to remove the background with the isnet-general-use model (see Highly Accurate Dichotomous Image Segmentation).
This was only necessary if the image was plotted using the PointSymbolizer. If plotted with the RasterSymbolizer, we can use comp-op="multiply" in the Mapnik stylesheet to remove any white background during the overlay operation.
IMG_TEST = OUTPUT / "images" / "test_image.png"
!../py/modules/base/pkginstall.sh "rembg"
Get Model
!wget https://github.com/danielgatis/rembg/releases/download/v0.0.0/isnet-general-use.onnx \
--directory-prefix {TMP} -nc --quiet
!ln -s {TMP}/isnet-general-use.onnx /root/.u2net/isnet-general-use.onnx 2> /dev/null
MODEL_NAME = "isnet-general-use"
from rembg import remove, new_session
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
SESSION = new_session(
model_name=MODEL_NAME,
alpha_matting=True)
#alpha_matting_foreground_threshold=240,
#alpha_matting_background_threshold=10,
#alpha_matting_erode_size=10)
def remove_background(img: Path, session=SESSION):
"""Remove background from image and overwrite"""
input = Image.open(img)
output = remove(input, session=session)
output.save(img)
%%time
remove_background(IMG_TEST)
img = Image.open(IMG_TEST)
img.thumbnail(size=(128,128))
img.show()

Place test image on the map¶
We can create a GeoTiff (^2) from this image and place it with Mapnik's RasterSymbolizer. Since Mapnik 0.6.0, there are also several Composition Modes available, including transparency.
ToDo: Test MarkersSymbolizer
Get coordinates
We test this with tagmaps cluster data for the TUD Campus area.
Data is already projected to UTM coordinates. Get the bounding box for BISMARCKTURM cluster. We want to place the tree image at this location on the map.
data_src = Path(INPUT / "shapefiles_campus" / "allTagCluster.shp")
focus_tag = 'BISMARCKTURM'
with fiona.open(data_src, encoding='UTF-8', mode="r") as locations:
map_crs = locations.crs
driver = locations.driver
schema = locations.schema
map_crs
Bbox = Tuple[float, float, float, float]
def add_buffer_bbox(
bbox: Bbox, buffer: int) -> Bbox:
"""Add buffer to bbox tuple (Meters)"""
return (bbox[0]-buffer, bbox[1]-buffer, bbox[2]+buffer, bbox[3]+buffer)
def bounds_str(bbox: Bbox) -> str:
"""Format bounds as mapnik-cli str"""
return str(bbox).lstrip("(").rstrip(")").replace(" ","")
def find_feature(data_src: Path, feature_name: str, add_buffer: Optional[int] = None, centroid: bool = None) -> Bbox:
"""Returns bounding box of a feature (x, y), if found"""
with fiona.open(data_src, encoding='UTF-8', mode="r") as shapefile:
for feature in shapefile:
properties = feature["properties"]
if properties["HImpTag"] == 1 and properties["ImpTag"] == feature_name.lower():
if centroid:
centroid = shape(feature["geometry"]).centroid
return centroid.x, centroid.y
bounds = shape(feature["geometry"]).bounds
if add_buffer:
bounds = add_buffer_bbox(bounds, buffer = add_buffer)
return bounds
Get bounds for Bismarckturm cluster
focus_bbox = find_feature(data_src=data_src, feature_name=focus_tag)
Get values as float
west, south, east, north = focus_bbox
To not skew the image, we only use the width of the cluster, and calculate the height in projected coordinates.
width = east - west
h_ctr =south+((north-south)/2)
south = h_ctr - (width/2)
north = h_ctr + (width/2)
Display map with buffer
map_buf = 50 # meters
focus_bbox_str = bounds_str((west-map_buf, south-map_buf, east+map_buf, north+map_buf))
Convert regular png to georeferenced raster by applying these bounds to the image.
raster.georeference_raster(
# raster_in=IMG_TEST, # raster with background removed with rembg
raster_in=OUTPUT / "images" / "test_image_white.png", # raster with white background
raster_out=INPUT / "test_image.tif", bbox=(west, south, east, north),
crs_out=map_crs, width_offset=map_buf, height_offset=map_buf)
Create map with the raster as an overlay and zoom in to the bounding box.
output_name = f"tagmap_production_{focus_tag.lower()}.png"
stylesheet = "tagmap_production_testraster.xml"
%%time
!/usr/bin/python3 -m mapnik_cli \
--stylesheet_name {stylesheet} \
--output_name {output_name} \
--map_dimensiony_x 500 \
--map_dimensiony_y 250 \
--input_path {INPUT} \
--output_path {OUTPUT} \
--bbox {focus_bbox_str}
display.Image(f'{OUTPUT}/{output_name}')

For placing multiple Raster images next to each other, we will have to write a few more methods to detect and avoid collisions, and offset images in these cases.
Use PointSymbolizer
Get centroid:
focus_centroid = find_feature(data_src=data_src, feature_name=focus_tag, centroid=True)
focus_centroid
Update the stylesheet and plot:
output_name = f"tagmap_production_{focus_tag.lower()}_pts.png"
stylesheet = "tagmap_production_testraster_points.xml"
%%time
!/usr/bin/python3 -m mapnik_cli \
--stylesheet_name {stylesheet} \
--output_name {output_name} \
--map_dimensiony_x 500 \
--map_dimensiony_y 250 \
--input_path {INPUT} \
--output_path {OUTPUT} \
--bbox {focus_bbox_str}
display.Image(f'{OUTPUT}/{output_name}')

The point symbolizer is both easier to use and produces better rendering (no skewed image; no black artifacts at edges).
Prompt tests¶
The parameters can be modified. The following cell activates the batch parameter and changes the sampling method. I also reduced the number of steps from 50 to 20, for reducing computation time.
SD_CONFIG["batch_size"] = 4
SD_CONFIG["sampler_name"] = "DPM++ 2M SDE Exponential"
SD_CONFIG["steps"] = 20
Next, improve our display method for batches
def remove_backgrounds(imgs: List[Path]):
"""Remove backgrounds for all images in list, overwrite"""
for ix, file in enumerate(imgs):
remove_background(file)
display.clear_output(wait=True)
print(f"Removed bg from {ix+1} of {len(imgs)} images.")
def generate_rembg(base_path: Optional[Path] = None, **kwargs):
"""Generate images and remove background"""
generate(**kwargs)
if base_path is None:
base_path = OUTPUT / "images"
imgs = list(base_path.glob(f'{kwargs["save_name"]}*'))
remove_backgrounds(imgs)
Also, Stable Diffusion doesn't require many words to focus on a topic. It was trained on a large corpus, based on common communication patterns that can be found online. E.g., below, we use a single "wave" emoji to generate illustrations in japanese line drawing style.
PROMPT = "(🌊)"
output_name = "test_image_emojiwave"
KWARGS = {
"prompt": concat_prompt(PROMPT),
"negative_prompt": BASE_PROMPT_NEG,
"save_name": output_name,
"sd_config": SD_CONFIG,
"show": False
}
%%time
generate_rembg(**KWARGS)
Show images in a grid
imgs = list((OUTPUT / "images").glob(f'{output_name}*'))
tools.image_grid(imgs)

The effect of all these parameters is quite difficult to judge.
The best way to test parameter effect is by observation.
Let's gradually change a single parameter, the weight of our Japanese line style LoRa, to study its effect.
def generate_series(
prompt: str, part: str, save_name: str, kwargs: Dict[Any, Any],
base_prompt_pos: Optional[str] = BASE_PROMPT_POS,
display: bool = True, rembg: bool = True):
"""Generate a series of images by
gradually modifying the weights for a part of the base prompt.
Weights will be substituted based on 1.0 occurence in the part-string.
"""
base_pos = base_prompt_pos.replace(part, "")
weight_steps = ["0.2", "0.4", "0.6", "0.8", "1.0", "1.2"]
for ix, weight in enumerate(weight_steps):
base_prompt_pos = f'{base_pos}{part.replace("1.0", weight)}'
output_name = f"{save_name}_{weight}"
kwargs["save_name"] = output_name
kwargs["prompt"] = concat_prompt(prompt, base_prompt_pos=base_prompt_pos)
if rembg:
generate_rembg(**kwargs)
else:
generate(**kwargs)
if not display:
continue
imgs = list((OUTPUT / "images").glob(f'{output_name}*'))
tools.image_grid(imgs)
The method will replace the default weight of 1.0 with steps from 0.2 to 1.2 and generate 4 images for each step.
SKWARGS = {
"part":"<lora:Japanese_style_Minimalist_Line_Illustrations:1.0>",
"base_prompt_pos":BASE_PROMPT_POS.replace("0.2>", "1.0>"), # reset to default
"kwargs":KWARGS,
}
generate_series(
prompt="(🌊)", save_name="test_image_wave", **SKWARGS)






We can see the progression towards the style of the Japanese Line Drawings. There seems to be an overweight for figures in the LoRa, which start to appear at a weight of 1.0. Below weights of 0.6, the LoRa only has a minimalist effect on generated images. In conclusion, maybe weights of 0.2 or 0.4 are good to reduce complexity of generated images towards a more minimalist style for the map.
Change the emoji from 🌊 to other emojis.
generate_series(
prompt="(🌳)", save_name="test_image_tree", **SKWARGS)






generate_series(
prompt="(🏡)", save_name="test_image_house", **SKWARGS)






generate_series(
prompt="(river, elbe, aerial)", part=LORA_PART,
save_name="test_image_scene", rembg=False)






Process data¶
The next step is to process social media metadata (tags, emoji) in descending importance (cluster-size), generate images for clusters, and place images on the map, according to the center of gravity for the cluster shape from tagmaps package.
Because this notebook got quite long, the processing is described in a follow-up notebook:
Create notebook HTML¶
!jupyter nbconvert --to html_toc \
--output-dir=../resources/html/ ./02_generativeai.ipynb \
--template=../nbconvert.tpl \
--ExtractOutputPreprocessor.enabled=False >&- 2>&-